Version française disponible ici !!!
Artificial Intelligence - The Q-Learning Algorithm.
Since i don't consider myself as beeing an AI guru, my purpose is neither to explore deeply the Q-Learning algorithm mechanism, nor it's theorical proof (which is, if i remember well, due to J.C. Watkins). This page remains volontary simple... For those looking to go further, please see the links section (bottom of this page).
In a few words: Q-Learning is a unsupervised reinforcement learning algorithm. The goal is to learn to a "software agent" how to optimally control a system (depending on the problem you'd like to solve ...). Q-Learning is very popular, mainly because it is quite easy to implement (the method's core does not exceed 5 code lines !!!). Unfortunately, Q-Learning is also quite difficult to parameter ...
Researchers involved in robotics where the pionneers using this method (in order to teach to their artificial creatures how to have a smart behaviour within their environment ...). A lot of other applications have been developped since then.
The reinforcement learning (RL) is, in my mind, related to the way babies are learning how to speak. Many successives tries, more or less randomly chosen, any try providing a variable reward, which is memorized. The goal is to determine, among all tries, which ones are best (that is, provide the greatest reward !).
Illustration : The baby just discovered he could make some noise with his voice. He keeps trying to say something, but, for now, all he "says" is meaningless ( "areuh, areuh,..."). Parents are happy since their kid has a fully functionnal vocal organ (except at 3 in the morning, but that's another story ...), but do not show some kind of extreme emotion (that is : unsuccessfull tries equal low rewards). One day, our little genius succeeds : he says "daddy" or "mummy", or any other meaningfull easy word. Parents are extremely proud and show their happiness to baby (successfull try equals high reward). The child remembers that successfull result, which reinforce it's language ability, and so on ...At the end of it's learning process, the child has progressively substitued a "random" strategy ( "I try to chain phonemes as they come ...") by a "control" strategy ("I know how to associate certain phonemes to build certain words ...").Even if this point of view is definitely too simplistic (acquiring a langage seems to involve much more than reinforcement learning), i find it usefull to illustrate in a very rough way the mechanism of RL.
Unsupervised learning is to be opposed to supervised learning methods, such as the now famous neural networks. In unsupervised methods, no previous knowledge is given to the software agent. It has a "blank memory" that will evolve along with it's experience. At the opposite, supervised methods feed the agent with a large amount of (most of the time statistical) data, and "supervise" that everything has been well digested. This may be quite annoying, because, for many problems, you DON'T have any data to provide ...
Of course, to perform an efficient learning, the agent must be able to determine, on it's own, the reward procured by any action he has performed, in any state. This implies that the agent must have functionnal perception means !
As an example is better than anything else, i wrote an demonstration JAVA applet.
Unless you already know, please take the time to read the following explanations lines, that will detail the context of the problem treated in that applet.
NOTE: This applet uses swing features (JApplet ...), so you'll need a recent java plugin (jre version >= 1.3) for your browser. Latest plugin available by browsing this site. Note to windows users : i suggest using the official java plugin from SUN rather than the microsoft implementation. You'll thank me later ..
The problem i decided to treat is VERY academic, but it helped me a lot to understand how Q-Learning is behaving (and how to set correct parameters values !!!)
Context of the problem:
A (virtual) robot - the agent - has to learn how to move on a grid map, made of three kind of cells:
The bot is able to move from cell to cell, using the fourth cardinal directions (North, East, South and West). It is aslos able to determine the nature of the cell it currently occupies (wether it is neutral, dangerous or a target cell). The grid is a square closed domain - the bot can't escape, but may hit the domain bounds ...
As long as it explores the grid, the bot receives a reward for each move it makes:
Please note that : at the very beginning of the learning process, or anytime the bot has hit a target cell, a new exploration process begins, starting from a randomly chosen position on the grid. And then, the bot restarts to explore the domain... (For mathematics addicts, this may be seen as a cycling, finite horizon problem ... Normally, Q-Learning is intended to be used for MDP (Markov Decision Problem) with infinite horizon, but it performs as well for cycling finite horizon problems ...
Using the Applet : A very short tutorial ;-D ...
Once the applet has loaded, you should see something similar to the picture below.
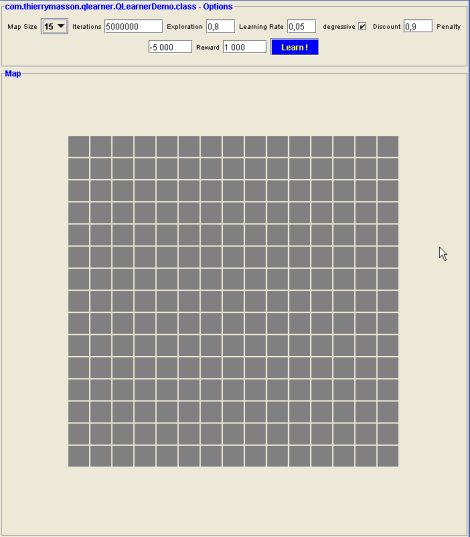
At first, you need to choose the size for the map, using the according selector. Three choices are available : 10, 15 or 20 cells (for any side of the map, which is square ...). Then the selected map appears, and the learn button is activated. I've chosen a size of 15, and it looks like this:
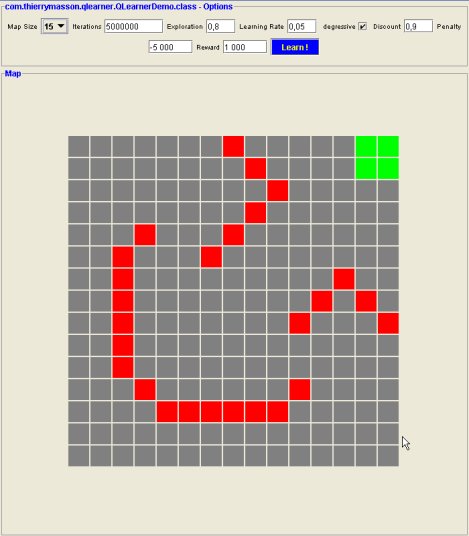
Next, you need to specify some dangerous and target cells, otherwise learning will be totally useless ... To perform that, use the mouse and click on the desired cell with:
Remember that, at least one target cell is required ! You can decide not to use dangerous cells, but you would certainly miss something, that is to say the evidence of the efficiency of the learning process ... Below is a sample configuration of my own:
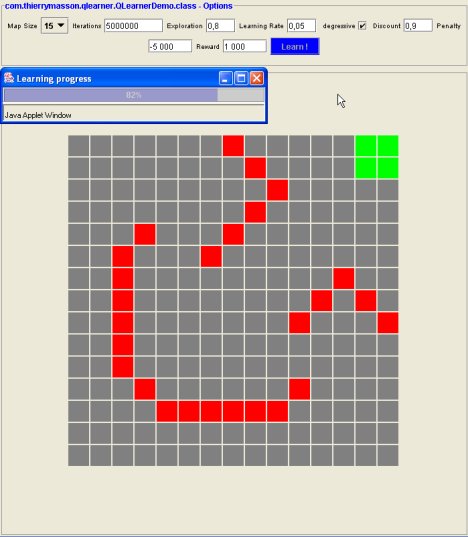
Then you can manually specify values for some of the parameters (see further explanations at the according section below), or keep the default values (which shall give good performance ...). Once you're done with it, just launch the learning process, using the "Learn !" button. The progress of the learning process is monitored using a progress bar, and this is how it may look:
Provided you have a recent processor, you should be able to view the results within a few seconds. When using all default values, it takes about 5 seconds to perform the whole learning process on my Athlon XP 1700+. Keep in mind that Q-Learning is known as a very greedy algorithm. It may consume a lot of memory and cpu time, when treating complex large problems ... Try to keep the iterations number as low as possible. The 5 000 000 default value performs well on 10 and 15 sizes. You may have to increase it a bit for treating a "20 cells per side" map.
Once learning process is achieved, the results are shown as follows:
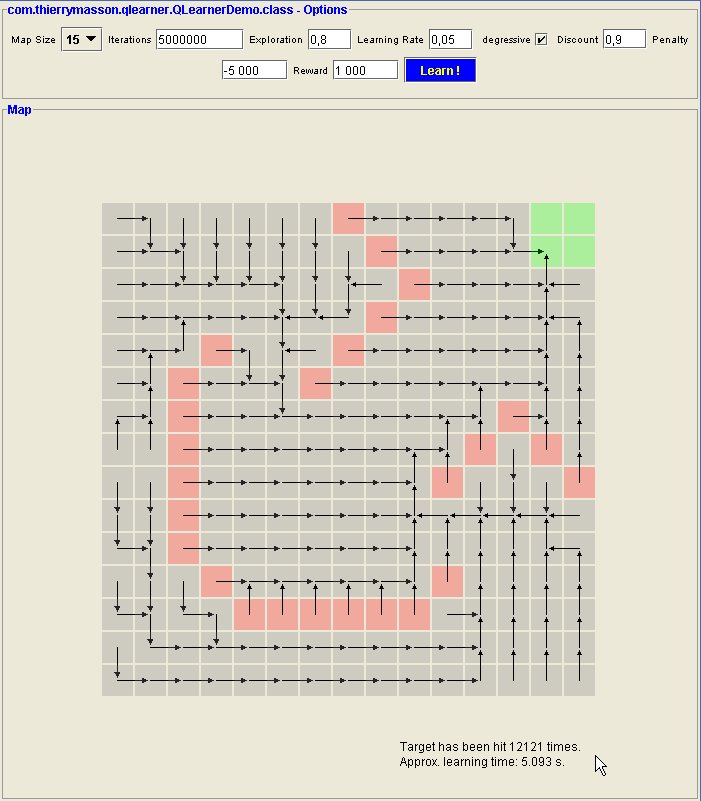
Interpreting the results:
As you can see on the preceding image, the map is now covered with arrows. These arrows symbolize what the bot considers as being the best move on each cell. I used a bit of transparency to keep the marks on cells visible. Note that if you press the "Learn !" button once again, the learning process will be started again on the same map. You can still click on cells to update their mark before launching a new learning session. Don't hesitate to experiment by yourself !!! I think the code is quite robust ...
Some additional stats are given in the lower right corners: the number of "hits" on the target(s), and the approximative learning completion time, in seconds.
You might be surprised that for a given map, all parameters being left unchanged, sucessives learning sessions won't give exactly the same results. This is in fact a normal behaviour, that can be easily explained:
The Q-Learning is known to converge to the optimal solution of the problem (see J.C. Watkins proof ...), but provided you let it make an infinite numbers of iterations !!! (which is, of course, PRACTICALLY IMPOSSIBLE!). Provided you let it do enough iterations, the Q-Learning will provide some QUASI-optimal solution (i.e. solutions that are close enough to the optimal solution, for being considered as "good practical" solutions). If the number of iterations is large enough, successives solutions will be very close (and near the optimal one ...). If successives solutions differ too much, you might need to increase the number of iteratiions to gain stability ... Keep in mind that the bot uses mostly random tries to forge it's experience ( about that see setting the exploration rate thereafter...)
As you may have already noticed, the problem i decided to treat looks like finding all shortest paths on a graph. More specific algorithms are dedicated to solve this kind of problems, and are much more efficient than Q-Learning. To my point of view, it would be silly to build a pathfinder using Q-Learning ... My purpose is only to show how Q-Learning behaves ...
Setting the parameters:
In the options panel of the applet, you'll see many customizable parameters (see picure below).

Some are related to the context of the problem, some are intrinsic to the Q-Learning mechanism.
Forgetting the map size, one can set:
The applet's page:
To go to the applet's page, click here.
To get the applet's java sources, please click here (using right button "Save Target As..." feature).
Links : to go much further ...
The reinforcement learning repository of university of Massachussets : THE major reference site dealing with R.L. A "must see" ... Lot of usefull links and ressources...